
I had an opportunity to review Cloud Storage Forensics recently, and I wanted to provide my thoughts on the contents of the book. I generally don't find book reviews that read like a table of contents (i.e., "...chapter 1 covers...ch 2 covers...") entirely useful, and I'm not sure that others would find them useful, either. As such, I'm going to approach my review in a different manner.
The book addresses digital forensic analysis of client systems used to connect to and make use of several "cloud storage providers". This is important to point out, as the terms 'cloud' and 'cloud storage' can so often be misunderstood. Some may think, for example, that this may have to do with those services available through Amazon Web Services.
The book primarily addresses three cloud storage providers...SkyDrive, Dropbox, and Google Drive...each accessed from a Windows 7 PC and an Apple iPhone 3G. In both instances, access to the storage facilities were conducted via the browser, as well as the client application for the particular provider.
Brett's review of the book can be found here. Brett is also the author of the sole review available on the book's Amazon page. It turns out that Brett was the technical editor of the book (he was also the technical editor for WFA 4/e, and he is the author of Placing the Suspect Behind the Keyboard), and as such, I was able to get a little bit of valuable insight into the process that went into getting this particular book published. This was as enlightening as it is important, because not all books, even books produced by the same publisher, follow the same process. A number of years ago, I was reading a book that was very popular at the time on the topic of computer forensics and incident response, and based on something I read, I contacted the authors to ask for clarification. One of the authors responded with, "...we wrote that section three years ago and didn't touch it before the book was published." So...not all books follow the "...sit down, write, review, publish..." format that is completed in a year (or less).
Pros
One of the things I liked about the book included the detailed, methodical approach that the authors took to populating their test environment with data, as it not only provides an excellent road map for testing, but also for reasoning during the analysis process. Too many times in DFIR work, too much is left to assumption, in part because analysts simply receive a hard drive or image, and are not equipped to address potential gaps between the data they observe, and the questions that they need to answer. One of the very first things I noticed about this book is the thorough approach taken to documenting the testing environment.
Also, the authors clearly stated the tools and versions that they used during their analysis. Some analysts may not realize it, but this is very important, as tools can very in their capabilities (sometimes, quite significantly) between versions.
Reporting
This aspect of 'full disclosure' (i.e., clearly identifying the tools and versions used) are near and dear to me, as they are a significant aspect of chapter 9, Reporting, of my upcoming book, Windows Forensic Analysis 4/e.
This aspect of 'full disclosure' (i.e., clearly identifying the tools and versions used) are near and dear to me, as they are a significant aspect of chapter 9, Reporting, of my upcoming book, Windows Forensic Analysis 4/e.
On the subject of the tools used, when I read the tool listing on pg 27 (I was reading the soft cover edition, not the Kindle edition), in ch. 3, I thought back to the "challenges face by law enforcement and government agencies" in ch. 1; it occurred to me that the reason the authors were using the tools on that list was that those are the tools most often used by law enforcement and government agencies.
The authors address a great number of data sources, including not just Prefetch, LNK files, and Event Logs, but also browser artifacts. The authors also explored (to some extent) what was still available in memory, as well. This can be very valuable, as analysts should consider parsing available hibernation files, as well as the pagefile.
The chapters that address the actual location of artifacts include additional information regarding the use of anti-forensic techniques (through the use of tools such as Eraser and CCleaner), and illustrate the artifacts that remain. Further, these chapters also include sections on Presentation, as well as tables that summarize the available artifacts. I had found this type of summary to be very valuable when teaching courses, and it works equally well in the book.
Cons
The book was published in 2014, and very shortly into chapter 3, it already appears out of date. For example, one of the tools used is "RegRipper version 20080909".
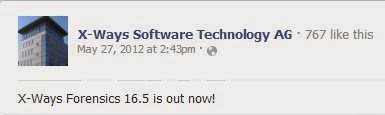
The version of X-Ways used in the book was version 16.5 which according to Facebook, first became available in May, 2012 (see the graphic to the right). Now, I'm not bringing this up to say that the most up-to-date version of a tool must always be used...not at all. But this information gives us a time frame to understand when the authors were writing the book. It also brings into question why some artifacts...in this case, shellbags) were not discussed, as some of the discussions of artifacts were alarmingly light. For example, on pg 40 (in ch 3), one sentence starts, "References were also found within the UsrClass.dat Registry files..."; clearly, the authors are referring to shellbags, but there was no further discussion of the artifact, nor anything that illustrated the artifact for the reader. A similar reference to artifacts in the UsrClass.dat Registry hive was made on pg 75 (ch 4) and on pg 105 (ch 5), but again, there were no further details.
What's also curious about the Registry hive file references is that when the client applications are used to access the cloud storage, there is no mention in any of the three instances (mentioned in the previous paragraph) of UserAssist artifacts. After all, it would stand to reason that when the user accesses the client application, they would most likely double-click an icon on their desktop, or click an entry on their Start menu...doing so would likely create artifacts in the UserAssist key. The Registry section on pg 105 in particular specifically mentions the use of "keyword searches", which would not locate entries in the UserAssist key, as the value names are ROT-13 encrypted.
Many of the artifacts (RecentDocs listing from the Registry, Recycle Bin, browser artifacts) displayed in figures and tables in the book include time stamps (which allows us to see when the research was conducted), but there are no analysis techniques illustrated beyond simply locating and displaying the contents of the individual data sources. Specifically, there are no illustrations of timeline analysis to illustrate not just the available artifacts, but how those artifacts might relate to each other. There were several examples of timelines (figures 3.2, 4.4, etc.), but these were used for presentation of data, not for data analysis.
Summary
The book is very well structured, had a very methodical approach, and as such, it's easy to locate information in the book. Each section is structured identically...when the Windows 7 PC is used to access SkyDrive or Dropbox, the sections listing the findings of artifacts are the same as when the iPhone 3G is used to access the same storage facilities. This structure provides a framework for other analysts who want to use updated, more recent versions of the platforms (Windows 8, iPad, iPhone 5+, etc.), as well as of the client applications for the cloud storage facilities.
However, the book was a bit light on the approach to artifacts; rather than taking a targeted approach to artifact (i.e., shellbags, etc.) analysis, and using timelines in the analysis of the systems, the primary means of analysis appears to have been keyword searches and the use of tools such as Magnet Forensics' IEF. There is nothing inherently wrong or incorrect about this approach, other than that this approach is known to miss certain artifacts (i.e., UserAssist data). I had hopped that the backgrounds of the authors, particular the number of forensic investigations undertaken by one, would have obviated sections of the book that included, "...keyword was found in the UsrClass.dat file...".
