Something that I've seen and been concerned about for some time now is the state of digital analysis, particularly when it comes to Windows systems. From open reporting to corporate blog posts and webinars, it's been pretty clear that there are gaps and cracks in the overall knowledge base when it comes to the incidents and issues being investigated. These "gaps and cracks" range from simple terminology misuse to misinterpreting single data points on which investigation findings are hung.
Consider this blog post, dated 28 April. There is not year included, but checking archive.org on 11 Sept 2023, there are only two archived instances of the page, from 9 and 15 June 2023. As such, we can assume that the blog post was published on 28 April 2023.
The post describes ShimCache data as being "a crucial tool" for DFIR, and then goes on...twice...to describe ShimCache entries as containing "the time of execution". This is incorrect, as the time stamps within the ShimCache entries are the file system last modification times, retrieved from the $STANDARD_INFORMATION attribute in the MFT record for the file (which is easily modified via "time stomping"). The nature of the time stamp can easily be verified by developing a timeline using just the two data sources (ShimCache, MFT).
The blog post also contains other incorrect statements, such as:
Several tools are available for analyzing shimcache, including the Microsoft Sysinternals tool, sdelete...
The description of the sdelete tool, captured from the SysInternals site on 11 Sept 2023, is illustrated in figure 1.
 |
| Fig. 1: Sdelete tool description |
As you can see, the sdelete tool has nothing to do with "analyzing" ShimCache.
Suffice to say, there is a great deal more that is technically incorrect in the blog post, but there are two important items to note here. First, when searching Google for "shimcache", this blog post is the fourth entry on the first page of responses. Second, the blog post is from a company that offers a number of services, including digital forensics and incident response.
I'd published this blog post the day prior (27 Apr 2023), listing references that describe ShimCache entries, as well as AmCache, and their context. One of the ShimCache references, from Mandiant, from 2015, states (emphasis added):
It is important to understand there may be entries in the Shimcache that were not actually executed.
There are a number of other free resources out there that are similarly incorrect, or even more so. For example,
this article was the tenth listing on the first page of results from the Google search for "shimcache". It was apparently published in 2019, and starts off by equating the ShimCache and AmCache artifacts. Further, the title of the blog post incorrectly refers to the ShimCache as providing "evidence of execution", and the browser tab title for the page is illustrated in figure 2.
 |
| Fig. 2: Browser Tab Title |
Similarly, artifact misinterpretation applies to AmCache entries. For example, this blog post that discusses Raspberry Robin includes the following statement:
...it is possible to evidence the execution of msiexec with the user's Amcache.hve artifact.
Aside from the fact that there is apparently no such thing (that I'm aware of) as "the user's Amcache.hve artifact", multiple rounds of testing (here, here) have demonstrated that, similar to ShimCache, the AmCache data source can contain references to executables that were not actually executed. This clearly demonstrates the need to cease relying on single artifacts viewed in isolation to support findings, and a need to rely upon validation via multiple data sources and artifact constellations.
I will say this, though...the blog post correctly identifies the malware infection chain, but leaves out one piece of clarifying, validating information. That is, when the msiexec command line is launched, a great place to look is the Application Event Log, specifically for MsiInstaller records, such as mentioned briefly in this Huntress blog post regarding the same malware.
These are just a couple of examples, but remember, these examples were all found on the first page of responses when Googling for "shimcache". So, if someone's attended training, and wants to "level up" and expand their knowledge, they're likely going to start searching for resources, and a good number of the resources available are sharing incorrect information.
And the issue isn't just with these artifacts, either. Anytime we look to single artifacts or indicators in isolation from other artifacts or data sources, we're missing important context and we're failing to validate our findings. For example, while ShimCache or AmCache entries are incorrectly interpreted to illustrate evidence of execution, where are the other artifacts that should also be evident? Are there impacts of the execution on the endpoint, in the file system, Registry, or Windows Event Log? Or does the Windows Event Log indicate that the execution did not succeed at all, either due to an antivirus detection and remediation, or because the execution led to a crash?
So, What?
Why does any of this matter? Why does it matter what a DFIR blog or report says?
Well, for one, we know that the findings from DFIR engagements and reports are used to make decisions regarding the allocation (or not) of resources. Do we need more people, do we need to address our processes, or do we need another (or different) tool/product?
On 26 Aug 2022, the case of Travelers Insurance vs ICS was dismissed, with judgement in favor of Travelers. ICS had purchased a cyber insurance policy from Travelers, and as part of the process, included an MFA attestation signed by the CEO. Then, ICS was subject to a successful cyber attack, and when they submitted their claim, the DFIR report indicated that the initial means of access was via an RDP server that did not have MFA, counter to the attestation. As a result, Travelers sought, via the courts, to have the policy rescinded. And they succeeded.
This case was mentioned here to illustrate that, yes, what's in a DFIR report is, in fact, used and relied upon by someone to make a decision. Someone looked at the report, compared the findings to the policy documentation, and made the decision to file in court to have the policy rescinded. For Travelers, the cost of filing was clearly less than the cost of paying on the policy claim.
What about DFIR report contents, and what we've got to look forward to, out on the horizon? On 21 Aug 2023, JD Work shared this tweet, which states, in part:
Threat actors monetizing nonpayment negotiations by issuing their own authored breach reporting...
Okay, wow. Yes, "wow", and that does seem like the next logical step in the the development and growth of the ransomware economy. I mean, really...first, it was encrypt files and demand a ransom to be able to decrypt them. Then, it was, "oh, yeah, hey...we stole some sensitive data and we'll release it if you don't pay the ransom." During all of this "growth" (for want of a better term), we've seen reports in the media stating, "...sophisticated threat actor...", implying, "...there's nothing we could do in the face of overwhelming odds." So, it makes sense that the next step would be to threaten to release a report (with screen captures) that clearly demonstrated how access was achieved, which could have an affect on attestation documentation as part of the policy process, or impact the responding DFIR firm's findings.
But is this something that will ever actually happen? Well, there's this LinkedIn post that contains the offering illustrated in figure 3.
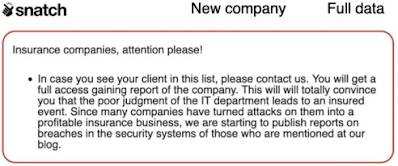 |
| Fig. 3: Snatch Ransom Note Offering |
"We will give you a full access gaining report of the company". Given what Travelers encountered, what impact would such a report have on the policy itself, had the DFIR report not mentioned or described the means by which the threat actor accessed the ICS environment? Or, what impact would it have on the report issued by the DFIR firm recommended by the insurance provider?
But wait, there's more! In 2007, I was part of the IBM ISS X-Force ERS team, and we became "certified" to conduct PCI forensic investigations. At the time, we were one of 7 teams on the list of certified firms. Visa, the organization that initially ran the PCI Council, provided a structure for reporting that included a "dashboard" across the top of the report. This dashboard included several items, to include the "window of compromise", or the time between the initial infection (as determined by the forensic investigation) and when incident was addressed. This value provided a means for the PCI Council to determine fines for merchants; most merchants had an idea of how many credit cards they processed on a regular basis, even adjusted for holidays. As such, the "window of compromise" could be used as an indicator of how many credit card numbers were potentially at risk as a result of the breach, and help guide the Council when assessing a fine against the merchant.
In 2015, an analyst was speaking at a conference, describing a PCI forensic investigation they'd conducted in early summer, 2013. When determining the "window of compromise", they stated that they'd relied solely on the ShimCache entry for the malware, which they'd (mis)interpreted to mean, "time of execution". What they hadn't done was parse the MFT, and see if there was an indication that the file had been "time stomped" ($STANDARD_INFORMATION attribute time stamps modified) when it was placed on the system, which was something we were seeing pretty regularly at the time. As a result, the "window of compromise" was determined (and reported) to be 4 yrs, rather than 3 weeks, all because the analyst had relied on a single artifact, in isolation, particularly one that they'd misinterpreted.
Breakin' It Down
The fundamental issues here are that (a) analysts are not thinking in terms of validating findings through the use of multiple data sources and artifact constellations, and (b) that accountability is extremely limited.
Let's start with that first one...what we see a good bit of in open reporting is analysts relying on a single artifact, in isolation and very often misinterpreted, to support their findings. From above, refer back to this blog post, which includes the statement shown in figure 4.
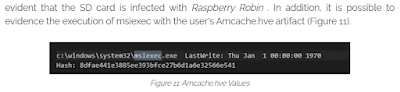 |
| Fig. 4: Blog statement regarding evidence of execution |
First, as I've tried to illustrate through this post, this artifact is regularly misinterpreted, as are others. Further, it is clearly an artifact viewed in isolation; when msiexec commands are run, we would expect to find MsiInstaller records in the Application Event Log, so there are corroborating artifacts within the constellation. These can be very useful in identifying the start of the installation attempt, as well as the success or failure of the installation, as was observed in this Raspberry Robin blog post from Huntress.
With respect to "accountability", what does this mean? When a DFIR consulting firm responds to an incident, who reviews the work, and in particular, the final work product? A manager? I'm not a fan of "peer" reviews because what you want is for your work to be reviewed by someone with more knowledge and experience than you, no someone who's on the same level.
Once the final product (report, briefing, whatevs) is shared with the customer, do they question it? In many cases I've seen, no, they don't. After all, they're relying on the analyst to be the "expert". I've been in the info- and cyber-security industry for 26 yrs, and in that time, I've known of one analyst who was asked by two different customers to review reports from other firms. That's it. I'm not saying that's across the hundreds of cases I've worked, but rather across the thousands of cases worked across all of the analysts, at all of those places where I've been employed.
The overall point is this...forensic analysis is not about guessing. If you're basing your findings on a single artifact, in isolation from everything else that's available, then you're guessing. Someone...whomever is receiving your findings...needs correct information on which to base their decisions, and from which they're going to allocate resources...or not, as the case may be. If the information that analysts are using to keep themselves informed and up-to-date is incorrect, or it's not correctly understood, then this all has a snowball effect, building through they collection, parsing, and analysis phases of the investigation, ultimately crashing on the customer with the analyst's report.
Addendum
I ran across this tweet from @DFS_JasonJ recently, and what Jason stated in his tweet struck a chord with me. The original tweet that Jason references states that it's "painful to watch" the cross examination...I have to agree, I didn't last 90 seconds (the video is over 4 min and 30 seconds long). Looking through more of his tweets, it's easy to see that Jason has seen other issues with folks "dabbling" in DF work; while he considers this "dangerous" in light of the impact it has (and I agree), I have to say that if the findings are going to be used for something important, then it's incumbent upon the person who's using those results to seek out someone qualified. I've seen legal cases crumble and dissolve because the part-time IT guy was "hired" to do the work.
Further, as Red Canary recently pointed out, the SEC is now requiring organizations to "show their work"; how soon before that includes specifics of investigations in response to those "material" breaches? Not just "what was the root cause?", but also, "...show your work...".
Addendum, 17 Sept:
Something I've seen throughout my time in the industry is that we share hypotheticals that eventually become realities. In this case, it became a reality pretty quickly...following publication of the ransomware attack against MGM, someone apparently from the ALPHV group shared a statement clarifying how they went about the attack. Of course, always take such things with a grain of salt, but there you have it, folks...it's already started.
On a side note, Caeser's was also attacked, apparently be the same group, and paid the ransom.














